
This company makes an AI exoskeleton to give people superhuman power
If you were curious when we’d start to see more AI exoskeletons promising to completely change how we do physical activities, you don’t have to …

If you were curious when we’d start to see more AI exoskeletons promising to completely change how we do physical activities, you don’t have to …

It’s not officially spring under the first tech events start to bloom, and it appears that Nothing wants to get in on that action with …

I’m less worried now about 3 Body Problem‘s prospects for getting a second season order from Netflix. That’s because, for the third week in a …

iOS 18 is Apple‘s upcoming operating system for its iPhone models, including the rumored iPhone 16. Expected to be announced during the WWDC 2024 keynote, …

It goes without saying that iRobot is obviously one of the biggest names in the robot vacuum market. So many of the company’s Roomba robot …

The iPhone 16 series won’t be announced until September, but I think we can already settle any design debates. Nothing can be truly confirmed for …

Wednesday’s roundup of daily deals includes some fantastic new offers that just popped up today. The star of the show is a rare 40% discount …

In a couple of months, Apple will preview iOS 18. While we expect this version to be the company’s major update in history thanks to …

In anticipation of this year’s Earth Day, Google on Wednesday announced new features for Google Maps and Search that should make travel more sustainable. The …

If you’ve ever tried Sony WF-1000XM4 or WF-1000XM5 wireless noise cancelling earbuds, you know that they’re among the best earbuds that have ever existed. It’s …

The iOS 17.5 beta cycle just started, and this might be Apple’s last iOS 17 update for iPhone users before it unveils iOS 18 during …

Navigating any instant messenger app can be a huge pain. It’s not just one-to-one chats that pile up each day on different platforms. It’s also …

The runaway success on Max of the docuseries Quiet On Set: The Dark Side of Kids TV has underscored what appears to be a core …

Black holes are a dime a dozen in the cosmos. These destructive and terrifying cosmic objects appear everywhere, including at the center of our galaxy. …

If I were to pick just one Spider-Man series from Sony’s multiple reboots, I’d pick Spider-Verse without thinking twice. I say that as someone who …

One of NASA’s biggest space missions is in deep trouble. The Mars Sample Return mission is currently on track to be one of the biggest …

Later this week, Taylor Swift will release her highly-anticipated new album, The Tortured Poets Department. The album will be on sale and streaming wherever you …

In March of 2021, NASA ground controllers released a cargo pallet of aging nickel hydride batteries from the ISS, the space agency shared in a …

In between running for the GOP presidential nomination, raising money, holding rallies, eating at Chick-fil-A, and serving as a defendant in what will be the …

The Apple Vision Pro features a sophisticated hardware and software experience that no augmented reality (AR) or virtual reality (VR) headsets available on the market …

Disney+ has an exciting month of new releases in store for subscribers this April. Whether you are searching for new originals taking place in the …

Sony is struggling to keep a lid on its unannounced PS5 Pro. Any questions you had about the “high-end version” of the PS5 (codenamed Trinity) …

We’re only halfway through April, and we’re already getting another round of title additions (and subtractions) from Xbox Game Pass. However, with every new game …

When Michael Lindsay-Hogg was tapped to direct a making-of documentary to accompany work on The Beatles’ 1970 album Let It Be, he had no way …

The 2024 solar eclipse was a brilliant cosmic display. While I didn’t get to see the totality for myself (I was out of town at …
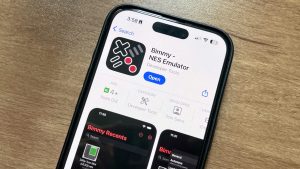
The first NES emulator for iPhone and iPad is now available on the App Store, following some recent App Review Guideline changes made by Apple. …

It’s been about a year and a half since the first season of Andor concluded, but the long wait for season 2 is finally coming …

It’s time for some indie games! We’re about two months out from Nintendo’s last Direct event, which the company hosted on February 21st, so it’s …

Insta360 once again pushes the envelope of 360-degree photography with the launch of its latest model, the Insta360 X4. As a very strong successor to …

watchOS 10.5 beta 2 is now available to Apple Watch users. After a mild update with watchOS 10.4, it seems this next version won’t bring …

tvOS 17.5 beta 2 is now available to everyone with an Apple TV that can run tvOS. At this moment, it’s unclear what this operating …




